

A better type of type |
 |
Date | 2020-07-18 |
|---|---|---|---|
| Tags |
This post is an introduction to an incredibly powerful pattern that is quite well established in the functional programming world but doesn’t seem to have percolated back to the OOP world, let alone modelling. Interestingly enough this pattern is all about abstracting from the way computers handle data values and bringing data description up to a more human friendly level. This pattern is known as the Algebraic Data Type.
Before we talk about algebraic data types, lets ask what is a data type? In software engineering, Data Types act like a translation rule between bits in the memory and some useful meaning to the user. Depending on the level of your programming language, data types abstract away the actual bits and bytes in the memory being used to store your data and provide you with meaningful values such as integers, characters and strings. Some data types though force you to think a little harder about the implementation, misunderstanding floating point arithmetic has lead to a number of high profile failures including a friendly fire incident of a missile system!.
There are a few different ways that programming languages treat types and values which I’ll go over quickly before we move on. Some programming languages are weakly typed. In these languages a programmer can feed any value into any function and the runtime will handle the errors if there are any. Lisp, Python and Javascript all live in this family.
Other languages are strongly typed. This mean that the language’s functions can only be used on a variable if the types match up. Having strong types means that the compiler prevents you from feeding values into functions that don’t know what to do with them preventing runtime errors but sacrificing some compiler efficiency. Examples of this are C (although casting allows you to be very cheeky with types), Java and the most rigid of the bunch, Ada. UML lives in this family too.
Finally, it is worth mentioning that there are strongly typed languages that have type systems (notably the Hindly-Milner type system) where the compiler can infer the required type signatures of function definitions. This is a significant advantage over languages such as Ada where a lot of type boilerplate code is required. Notable examples in this family are Haskell and OCaml. Some of these types systems are powerful enough to be used as mathematical theorem provers like Agda and Idris which may pave the way to provably safe code in the future once the paradigm has taken hold.
In UML terms, however, a data type is defined as a classifier whose instances are anonymous. This means that its just a class with unnamed objects (the objects are unnamed as they correspond to values). UML gives us three kinds of data types: structured data types (a name given to any type that contains an attribute of another type) primitives and enumerations. Enumeration is an interesting choice of name because it evokes the underlying mechanism of the abstraction (though was probably chosen to match enumeration types in C, a decision mirrored in the Rust programming language). Primitive data types are a UML cop-out:
A PrimitiveType defines a predefined DataType, without any substructure. A PrimitiveType may have algebra and operations defined outside of UML, for example, mathematically. The run-time instances of a PrimitiveType are values that correspond to mathematical elements defined outside of UML (for example, the Integers). [1]
I personally object to this part of the standard and believe that types and their associated operations shouldbe brought into UML so that we can reason about which types best convey requirements and allow model checkers to catch type misuse errors.
Part of the argument that I will try to convey in this post (but mainly the future one on typeclasses) is that knowing the possible values that a data type can take and what functions can be performed upon it are not a critical part of a UML/SysML design. This would enable use of UML/SysML model checking to ensure that we’re not introducing type errors at the requirements level: if you try to feed something of the wrong type into the wrong function in your UML model, letting the model pick that up saves some poor programmer having to try and implement contradictory requirements. This blog post will introduce algebraic data types through a motivating example and then explore a candidate notation for defining them in UML.
Algebraic Data Types
The name “algebraic data type” tends to conjure up images of complex maths but its simply and abstract pattern to enable us to define new data types as the “sum” or “product” of existing data types. The product of types is already familiar to most modellers and programmers, it occurs when one type has values that are a combination of two or more other types. These are known as tuples when the constituent values are not named and are called structures or records when the constituent values are named. In UML this is just the structured data type.
The sum of two (or more) types, sometimes called a “union”, is a new type that has all of the values of both of the types. In UML enumeration data types can be thought as the union of each of its enumeration literals. UML enumeration literals are not quite suited for this purpose as they mst have a defined set of values that cannot be generated by a function. Some modellers try and get around this by using inheritance as a means to show that a data type can be either one value or another. The problem in this case is that the “input” data types to the sum cannot exist independently of the “output” (the super class) which does not convey the desired information to the reader of the model. This is why we will need to introduce a new notation for this concept.
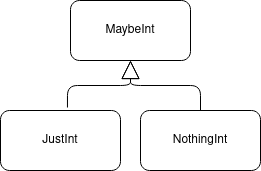
A nice introduction to this concept can be found in the guide to the Elm programming language: Types as Sets
Failure in the system
To introduce the usefulness of algebraic data types, lets investigate a common systems engineering problem; how to represent failure in the system. Imagine an operation in a model that divides two real numbers. In a UML model we would see something like this in the browser:
Divide(a : real, b : real) : realNow imagine that we have performed some sort of HAZOPS process on the model and found that this function cause some quite spectacular problems when we try and divide by 0.
Don’t panic though, this is easily caught by the operation itself if we check to see if b is 0. We can catch that error easily, but how do we communicate to downstream functions that Divide has failed? Here are a few solutions:
1) Add an extra failure line
Probably the most trivial answer, this solution just adds a separate failure propagation output to the function.

It doesn’t take much extrapolation to see how quickly this would get completely out of hand, doubling up all of the lines on your diagram. UML only allows one return type, in the diagram the failure is considered an “argument by reference” but the failure could have been the return type instead. The language does not have a convention in this case making reusability awkward. Now imagine if the upstream function could fail too, we’d need to add another two inputs! And how would these received failures map to the output? This approach is definitely not scaleable.
2) Pick an arbitrary value to represent the failure
This time we will pick an unused value of the data type to represent the failure. This is often the favoured approach of simulink engineers. If your data type is an int, enumerate your failures from 255 back &c. This is most likely how a good compiler will implement your software error propagations anyway, but it doesn’t preserve the meaning inside the model in a meaningful way. It defeats the point of modelling somewhat as it forces the reader to think further down the abstraction layers. It also causes problems if the value range of the data type has to change.
This method is also a step back from the first option in terms of reusability, if you are required to reuse this function in a context where the error value is required as part of the nominal range, you’re going to have to define a new one with a new error value. This solution is a case of the antipattern “genetic disorder”. If the implementor of the software is using a language like Haskell to code the solution (see below for the Haskell solution), you have forced their hand through the misuse of UML/SysML to create a solution in the software that is considered bad practice for that language. This happens a lot with UML when trying to implement specified behaviour in a different programming paradigm from OOP.
3) Use the Maybe pattern
There’s no diagram for this case as like case 2, we’re embedding the concept of failure into the very data type itself. except in this case, the language is powerful enough to let us embed the idea of failure into the data type without the use of a unscaleable bodge. As a motivating example from a programming language with these concepts baked in, Haskell has a pretty elegant syntax for the Maybe concept:
Data Maybe a = Just a | NothingThis is a Haskell type constructor declaration that tells us that we can create a Maybe type for any existing type (the a term in the declation which is basically a template parameter) which, when fed a type (such as Int) creates a type that may be an Int or may be nothing.
To illustrate how this would be used in Haskell, the SafeDivide operation would be implemented using the following syntax:
safeDivide :: (Int, Int) -> Maybe Int
safeDivide (_ , 0) = Nothing
safeDivide (a , b) = Just (a/b)The first line tells us that safeDivide is a function that takes two integers and returns a Maybe Int. The second line tells us to return Nothing if the denominator is 0 and not worry about the numerator in this case (an underscore in Haskell means any value). The third line tells us that for all other input pairs, return the division wrapped in a Just. The next function can then check to see if the input is a Nothing or a Just and act accordingly.
A great introduction to this programming pattern is the slide show on “Railway Oriented Programming” on F# for fun and profit. If you have a play with functions of the type a -> Maybe a you’ll probably quickly come up against a few problems of how to chain them together. This is especially true if you’re trying to concatenate errors with Maybe’s cousin, Either. To solve these problems we’ll have to learn about more patterns such as Functors, Applicative Functors and Monads which are out of the scope of this post but I promise I’ll cover them at a later date!
Baking in ADTs
Lets imagine that we could design ADTs within UML, such as the Maybe type, what could the syntax look like? As we discussed earlier, to create ADTs, we require the ability to define new data types as the sum of two others or the product of two others. As a starting point, lets create two specialisations of directed associations to represent our constructors: one called «product» to represent the cartesian product of 2 or more types and an n-ary association called «union» to represent that the owning type is a union of two or more types. The product type is relatively familiar as it already exists in UML as a structure, we are just using the associations to make it diagrammatically explicit. Now we have defined an extension for sum types, we can use them to create definitions for all sorts of new types:
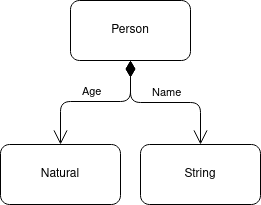
Here we are using the normal composition relationship to show that this type is a product of the two others. The name of the product relationship acts as the name of the “property” in the data type in a similar way to the way members of a class’s names show on the composition association.
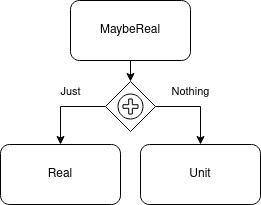
In this case the data type is the sum of two others. This is a tagged union; the names on the sum association give us a tag that we can use to reference the values of the constituent types.
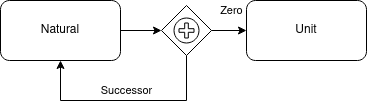
In this diagram, we are using the standard type theoretic inductive definition of the natural numbers. We can read this as: a natural number is either 0 or an increment of a natural number. This is probably the most simple type to define in this system but it shows how we can use ADTs to define data types from scratch within the language itself. Note the “Unit” data type is a type with one value. This is needed to make the algebra of algebraic data types an algebra (a semiring to be exact). There should also be an Empty type that acts as the identity of the product type.
Let’s think about this definition mathematically for a minute. What does this definition actually say? Well, we can think of the nothing type as “0” and increment as “+1” so our natural numbers are:
0 or 0+1 or (0+1)+1 or ((0+1)+1)+1 or …
Which is very much the definition of the natural numbers! Can we apply this sort of recursive definition to more exciting (and far more useful) data types? of course! Lets see how we can define the idea of a list inside of this profile:
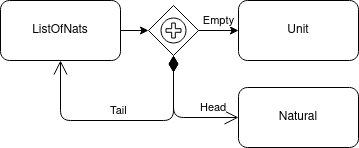
In this diagram we have defined a list of natural numbers to show how even more interesting types can be defined. Here we can see that a Nat List is defined as either the empty list or a product of a natural number (the head of the list) and a list of natural numbers (the tail of the list). In a way, the list type is a Maybe type that can contain more than one value.
You’re probably looking at the above image right now and already thinking why should we have to define a new list type any time we need a list of things of a certain type. Especially when the pattern is such that we could replace the data type “Nat” on this diagram with any type that we could imagine (including other list types to make lists of lists). There is definitely an opening here to provide some abstraction and reuse value by creating “template” data types as we saw earlier with the Haskell maybe constructor. For now though I’ll leave this for another blog post.
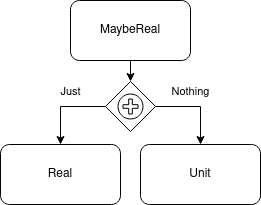
And finally, here’s the definition of the MaybeReal used in the motivating example.
As an exercise, why don’t you try this out yourself and create a diagram to define a binary tree of integers using just the elements described in this section?
Next time in this series I’ll talk a little more about how we can generalise these data types for even greater reuse value: Data type constructors and type classes. These are the tools that we can use to create versions of maybes and eithers that can be strung together to allow us to specify systems more abstractly without having to rely on C, C++ and Java language constructs.
References
[1] OMG 2017 OMG™ Unified Modeling Language™ (OMG UML™) Version 2.5.1 http://www.omg.org/spec/SysML/1.4/